
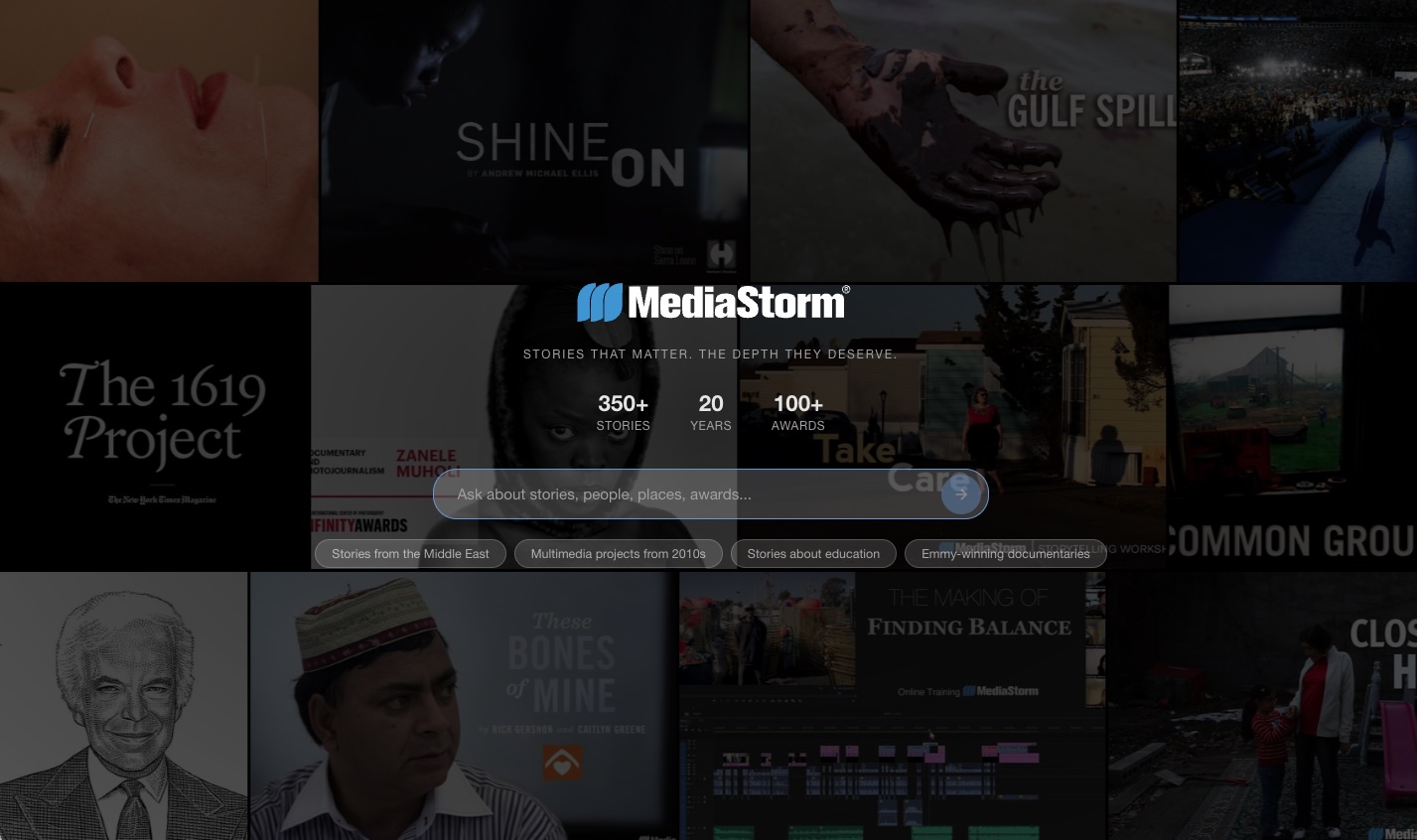
The uber talented Tom Vaillant recently attended a MediaStorm workshop and that kicked off a series of follow up conversations. Tom is a terrific storyteller and also an innovative technologist focused on investigative journalism using data and AI. He suggested that there could be a way to improve access to our archive of over 350 films by using semantic search which allows natural language queries by theme, connection or meaning.
As Tom Says: “We ingested every published story, enriched it with AI-extracted metadata — topics, entities, themes, key quotes — and wired up hybrid retrieval with a visual gallery. Runs locally at query time, no API calls. Every media organization sits on an archive. Decades of footage, transcripts, reporting — catalogued well enough to store, but not well enough to search by meaning. AI changes that equation. It turns archives into knowledge bases — searchable, structured, and accessible in ways that weren’t possible before. The librarian that never forgets. MediaStorm’s archive is well-catalogued — titles, descriptions, full transcripts with speaker attribution. But 350 stories spanning two decades hold more than keyword search can reach. The goal was to give the archive a deeper layer of access — searchable by theme, tone, narrative structure, not just words that happen to appear in a title.”
Here is the prototype that Tom created:
https://archive.mediastorm.com
And the case study he wrote:
https://buriedsignals.com/cases/mediastorm